about:memory and the memory reporter infrastructure that powers it are amazing. They provide an explicit hierarchy that breaks down the memory use in the system to the subsystems and increasingly the causes of allocation. about:memory looks like this (if you stand a few feet back from your monitor and take off your glasses):
 about:memory session")
If you are going to look at about:memory, it is probably for one of two reasons:
- You are Nicholas Nethercote or one of his merry band of MemShrink hackers kicking ass and taking names (of inefficient uses of memory). In this case, about:memory is exactly what you need.
- You suspect some tab in Firefox has gone crazy and you want to figure out which one it is and take your vengeance upon it. Vengeance can take the form of thinking mean thoughts, closing the tab, or writing a snarky tweet. about:memory will let you do this, but you have to look at a lot of text and you may already be too late to find the culprit! If only there was an easier way…
Enter about:nosy:

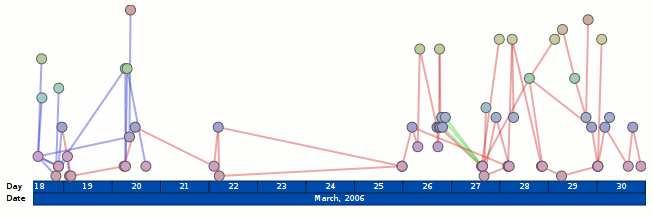
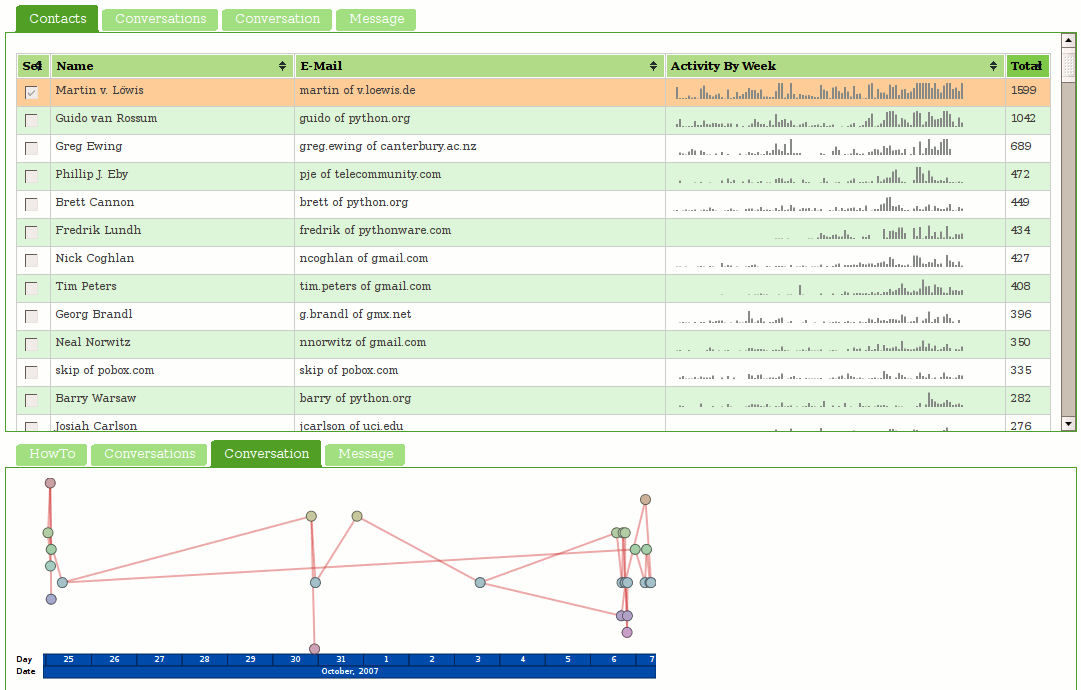
It can show us a list of all the open tabs and their memory usage sans JS for now, as per the above screenshot. If you expand the tab capsules, you get to see the list of all the inner windows/iframes that live in the hierarchy of that page. In most cases the list is either really short and boring or really long and boring. In the case of www.cnn.com I end up with 26 inner windows.

It can also show us memory aggregated by origin. We do show JS for this case because JS is currently only trackable on a per-origin basis. When Bug 650353 gets fixed or the memory reporters get more specific we should be able to apportion JS usage to pages directly.

It also attempts to aggregate extension JS compartments back to their owning extension. We ask the add-on manager for a list of the installed extensions to find their filesystem roots, ask the resource protocol to explain resource mappings, and from there are able to translate such paths. Just keep in mind that traditional overlay-based extensions do not create their own compartments and so are invisible for tracking purposes.
In the screenshot above, you can see that about:nosy keeps the charts exciting by generating a ridiculous amount of garbage all by itself. Much of this is just the about:memory tree-building code that we are reusing. If you refreshed about:memory once a second you would probably see similar garbage creation from the main system JS compartment.
You can install a restartless XPI (update: points at 0.3 now which does not screw up style shell apportionment and uses a better add-on SDK that does not create throwaway JS compartments every second) of the state of the now that will not auto-update. It wants a recent nightly build of Firefox because it makes assumptions about the structure of the memory reporters in order to better serve you.
You can find the source repo on github. It requires the add-on SDK to build. It might seem a little overkill for just graphing memory history, but if you’re looking at the repo you will notice my goal is to use Brian Burg‘s jsprobes work aided by Steve Fink and now de-bitrotted by me (but still a bit crashy) to be able to graph CPU usage, including raw JS, layout/reflow, and paint (eventually, after adding probe points). It’s also possible for those statistics to be gathered via static mechanisms, but the probes are fun and I want to see them work.