The deuxdrop messaging experiment‘s current incarnation exists as an (under development) Jetpack that runs in Firefox. I am still trying to shake out functionality to be driven by the UI rather than headless unit tests. While firebug has been a great help, another boon has been the logging framework and log viewing framework developed for the unit tests. (Previous posts here and here). Since the log is made up of structured JSON data, all the log processing logic is written in JS, and the log viewing UI is HTML/CSS/JS, it is trivial to embed the log viewer into the Jetpack itself.
If you type about:loggest in the URL bar (or better yet, create a bookmark on the bookmark bar and click that), the log viewer is displayed. Deuxdrop’s client daemon logic (which runs in a hidden frame), uses a log reaper that runs at 1-second intervals. If anything happens log-wise during that second, it is packaged and added to a circular-buffer style list of the last 60 seconds where anything happened. When the log viewer starts up, it asks for and receives the data. The result looks like the above small screenshot. If no errors were logged during the time interval, it is automatically collapsed.
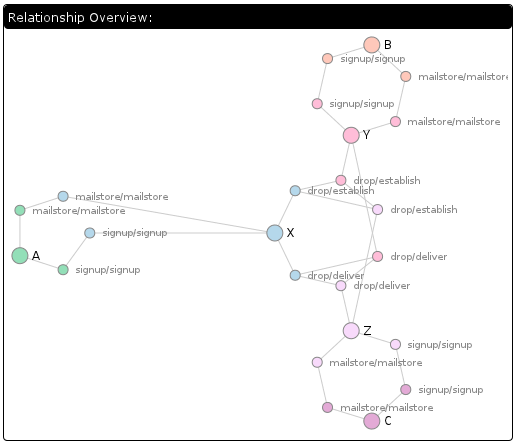
Let us experience the joy of integrated logging by looking at a real problem I recently encountered. In the development UI (accessible via about:dddev), I brought up a list of my contacts after starting a conversation. It looks like this right now:

The problem is that I, the user, am “Andrew Sutherland” and should not be in my own contact list. Also, the display should not be claiming there are an undefined number of unread messages from me, but that is likely fallout from the system intentionally not maintaining such information about me, the user.
I want to quickly figure out why this is happening, so I bring up about:loggest and open the most recent time entry to see what happened when this query was issued and filled:

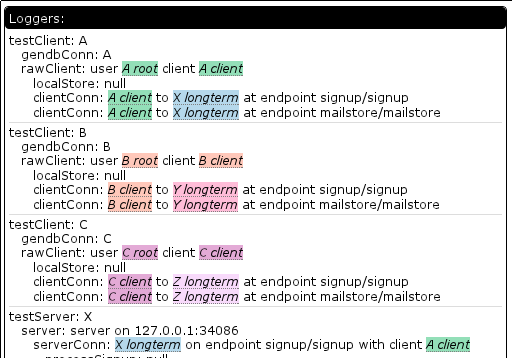
I can see that the query ended up issuing database requests for both Walternate (purple) and myself (green), strongly suggesting that the database index being queried on names me.
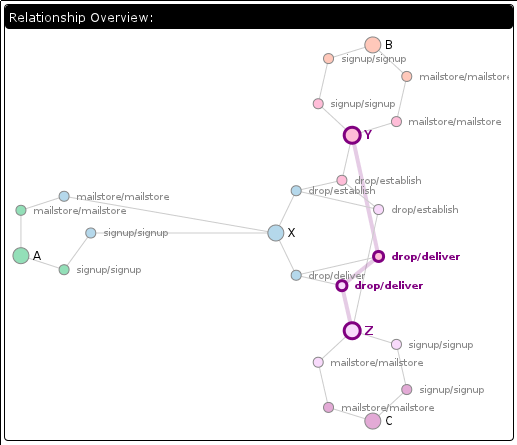
I wonder if the conversation processing logic was the code that did this… let’s check by going to the time slice where the conversation was processed, expanding it, and only screenshotting some of it:

Yes, the conversation logic did this. It’s generating index values in the peepData table for the idxPeepAny and idxPeepRecip indices. But I thought my unit tests covered this? Nope. It turns that although we test that a peep query returns the right thing both cold from the database and inductively via notifications as contact relationships are established, we don’t issue a new query after creating a conversation. Furthermore, we only issued queries against the alphabetical index, not against idxPeepAny. So we rectify that by augmenting the unit test:
// - make sure that the conversation addition did not screw up our peeps list
T.group('check peeps list after conversation join');
lqFinalAllPeeps = moda_a.do_queryPeeps("allPeepsFinal:any", {by: 'any'});
And the test indeed now fails:

The relevant bit is in the lower right, which I blow up here with the “unexpected event” obj popup displayed above it, and the “failed expectation” obj popup below it. The postAnno stuff is to indicate what is new in the query result. Because it’s a freshly issued query and this is the first set of results, everything is new. It’s probably worth noting that these errors would usually show up as a single “mismatched” error instead of an unexpected/failed pair in our tests, but the specific logger was operating in unordered set mode because we don’t care about the exact order that different query notifications occur in, we just care that they do occur.

(The structure is intended to later be enhanced to provide a nicer visualization where we only show the contents of the “state” attribute and use preAnno to indicate annotations on a representation of the most recent state for the object (from a previous log entry) and postAnno to indicate annotations on the now-current representation “state”. For postAnno, values of 1 represent an addition, and values of 0 represent a change or event firing on the object.)
A potentially even more exciting bit of integrated logging is that about:loggest-server opens a tab that retrieves its contents from the server. When run with the –loggest-web-debug flag, the server loads a module that cranks up the logging and does the same 1-second interval log reaping magic and exposes it for HTTP retrieval. While this specific configuration with the high level of detailed logging is only appropriate for a developer-machine test server, it is incredibly valuable to be able to just pop open another tab and see what the server just got up to.
In any event, I leave it as an exercise to the reader to assume that I will take care of the bug now that it’s extremely clear what the problem is. Well, extremely clear if I had taken a bigger screenshot of the conversation creation log. Above the region captured is a header that indicates the actions are being triggered by the ‘convJoin’ task and the entry (which is visible) indicates the update_conv_data function likely kicked off the database activity.
PS: All the gibberish looking characters in the screenshots are crypto keys or other binary data that lack aliases mapping them to known objects. Examples of successfully mapped aliases are the colored blocks. In the case of the conversation creation gibberish, we are seeing the conversation id. Those aliases are generated as a separate pass by the log reaper by walking the set of existing queries and using helper functions to map the items currently exposed by the queries to human names because it’s quick and easy and is O(what’s being looked at) not O(size of the database). In the case of the conversation, there was no query against the conversation and I also have not written the helper function yet, which is why it did not get aliased. Unit tests don’t have the problem because we create aliases for everything.